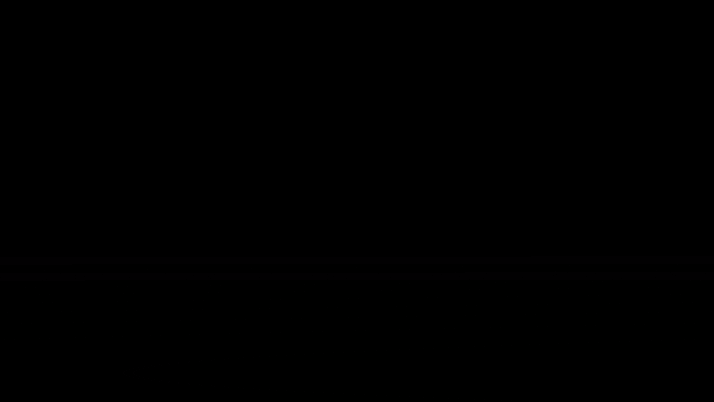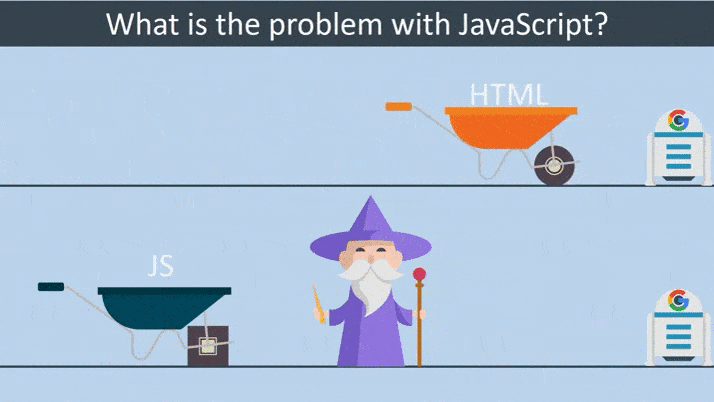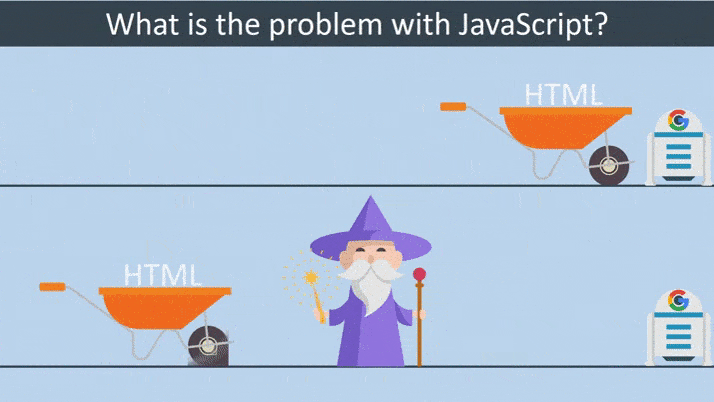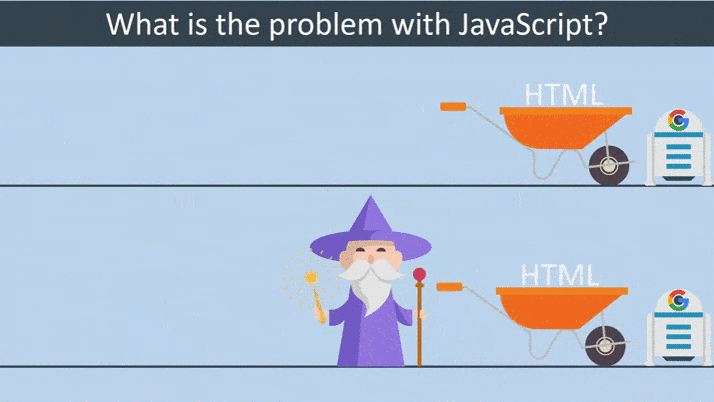JavaScript makes the web dynamic and interactive – and that’s something that users love. JavaScript runs seamlessly for the user and allows us, here at Tabs, to implement bespoke user interfaces and experiences on a whole new level. But what about Google and other search engines? Can they easily deal with JavaScript?
In the case of crawling traditional HTML websites, everything is straightforward and the whole process is lightning fast. Googlebot downloads an HTML file and then extracts the links from the source code and can visit simultaneously. It then downloads the CSS files and sends all the downloaded resources to Google’s Indexer, for which it indexes the page.
Things get complicated when it comes to crawling a website that heavily relies on JavaScript. Googlebot downloads an HTML file. Googlebot does not find links in the source code, as they are only injected after executing JavaScript. It then downloads the CSS and JS files. Googlebot has to use the Google Web Rendering Service to parse, compile and execute JavaScript. WRS fetches the data from external APIs or from the database. The indexer can index the content. Then, Google can discover new links and add them to the Googlebot’s crawling queue.
Difference between HTML based and JS based website rendering
Will Google render my Javascript?
Yes, but with some caveats. The following things should be taken into account:
1) Parsing, compiling and running JavaScript files is very time-consuming – both for users and Google.
2) In the case of a JavaScript-rich website, Google can’t usually index the content until the website is fully rendered.
3) The rendering process is not the only thing that is slower. It also refers to the process of discovering new links. With JavaScript-rich websites, it’s common that Google cannot discover any links on a page before the page is rendered.
4) JavaScript is a programming language that must be compiled to run; any syntax that is not valid for specific JavaScript version will crash compilation.
5) Googlebot is based on the newest version of Chrome. That means that Googlebot is using the current version of the browser for rendering pages. Googlebot visits web pages just like a user would when using a browser. However, Googlebot is not a typical Chrome browser.
6) Googlebot declines user permission requests (i.e. Googlebot will deny video auto-play requests).
7) Cookies, local, and session storage are cleared across page loads. If your content relies on cookies or other stored data, Google won’t pick it up.
8) Browsers always download all the resources – Googlebot may choose not to.
9) Changing canonical tags via JS is considered not reliable by Google. So make sure you have your canonical URLs in the HTML and not JS. Chances are Google may have addressed this issue but it’s just a chance, and when it comes to SEO one should not risk it unless dead sure.
Further to the above, Google’s algorithms try to detect if a given resource is necessary from a rendering point of view. If it isn’t, it may not be fetched by Googlebot. Because Googlebot doesn’t act like a real browser, Google may not pick some of your JavaScript files. The reason might be that its algorithms decided it’s not necessary from a rendering point of view, or simply due to performance issues (i.e. it took too long to execute a script). If your content requires Google to click, scroll, or perform any other action in order for it to appear, it won‘t be indexed. And last but not least: Google’s renderer has timeouts. If it takes too long to render your script, Google may simply skip it.
When you surf the internet, your browser (Chrome, Firefox, Safari) downloads all the resources – from images to scripts – that a website consists of and puts it all together for you.Since Googlebot acts differently than your browser, its purpose is to crawl the entire internet and grab valuable resources. Google optimizes its crawlers for performance. This is why Googlebot sometimes doesn’t load all the resources from the server. Not only that, Googlebot doesn’t even visit all the pages that it encounters.
Server Side Rendering or Client Side Rendering?
Server Side Rendering: with SSR or Server Side Rendering the content is already there when the browser receives it. It means it’s not just easier for the bot to crawl but is extremely fast as it’s classical HTML approach.
Client Side Rendering: with CSR or Client Side Rendering the browsers have to struggle a bit as it might receive little or not content at all on initial load and fetch more content later with Asynchronously with JavaScript. With CSR you have to make sure your website is crawlable by the bot.
Crawlers and Search Engines are made capable enough to parse, render and index JavaScript based website like they crawl HTML based websites. But it’s up to us developers to make your websites obtainable and crawlable, and to understand how modern JavaScript websites and their SEO work. Get in touch with us today and learn how to best optimize your website for Search Engines and Bots.